Linear Regression
Consider a bunch of error prone measurements made under different conditions conditions that should have been related linearly as , but are instead related as . Usually, to minimise this error, you would make the measurement multiple times in the same conditions and then use the average of those measurements as your . In such a condition, due to the central limit theorem, would follow a Gaussian distribution if you had taken infinite number of such measurement under the same conditions . Notice we are assuming that the error, in limit, follows the same distribution for each ..basically are i.i.d. variables . Thus, the probability distribution for would be . This is what should happen for the correct value of .
The main problem is that we don’t know this correct , and so what we do is that we pretend for any general value of that it’s correct, in order to find the probability of our data being the way it is in that case, namely , and then using this probability and Bayes’ rule, we find , which is the probability that our guess for is correct. Thus, although we don’t know the correct value of , we can find the most probable value, and just go along with it, since it explains the data the best. Note that is the probability of the event that we observed AND the conditions are , given that is its true value. This can be written as . It’s safe to say that the conditions we have for the observation and the way that the observations are related to these conditions, which is represented by should be independent. Thus we can write . And thus . And so, after using Bayes’ rule, we would have
as all other terms are independent of . So to find the most probable , we just have to maximise .
Maximum Likelihood Estimate
A common way to simplify this expression is to set the prior distribution . The expression thus obtained is , which is the Likelihood for . Equivalently, we can minimise the negative log likelihood, which is given by
.Discarding a bunch of constants, we just have to minimise :
where is the matrix made of the row vectors .
This is the loss function, divided by the number of observations is known as the Means Squared Error.
Differentiating this loss function wrt , we get the gradient
This can be used for gradient descent directly. But in this case, we can find the solution directly by setting the gradient to 0
Maximum A Posteriori Estimation
Remember how we discarded by setting it to 1 ? We did so because we knew nothing about . If we did know something, then we can get a better estimate. For example, if has a Gaussian distribution , then we get a more general estimate :
Setting to , we get the previous estimate.
Linear regression in action
Importing libraries
from matplotlib.pyplot import *
from numpy import *Example 1
Generating Data
x1 = 10+2*random.random((1000,1))
x2 = 1+3*random.random((1000,1))
sig = 0.3
noise = random.randn(1000)*sig
y = sin(2*pi*x1[:,0])+cos(2*pi*x2[:,0])+noise
X = concatenate((x1,x2),axis=1)
del x1,x2
X,X_test = X[:800,:] , X[800:,:]
y,y_test = y[:800] , y[800:]Plotting to get a feel
scatter(X[:,0],y,c=X[:,1])
figure()
scatter(X[:,1],y,c=X[:,0])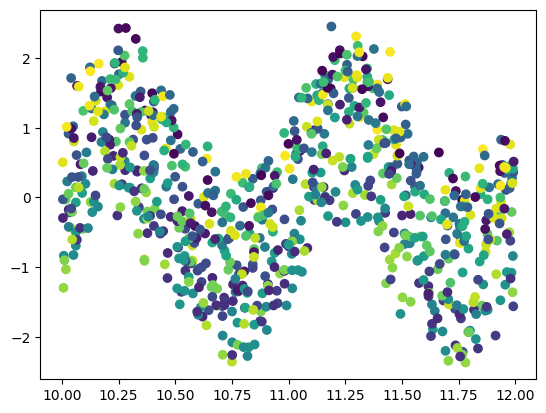
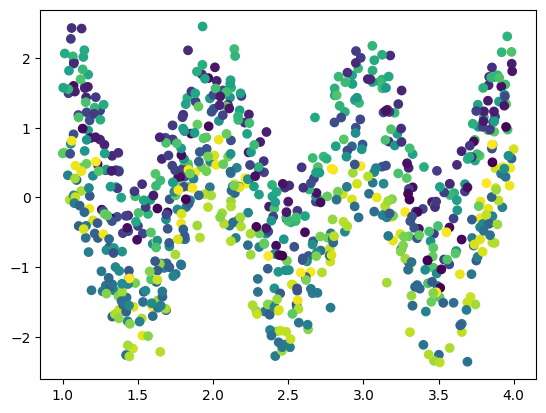
Now that we have figured out that the relationship is sinusoidal, we can assume and find the best value of .
def f(X):
X = 2*pi*X
return concatenate((sin(X[:,newaxis,0]),sin(X[:,newaxis,1]),cos(X[:,newaxis,0]),cos(X[:,newaxis,1])),axis=1)
F = f(X)
theta = dot(linalg.inv(F.T @ F) @ F.T ,y)
print(theta)[ 1.02137996 -0.00515224 -0.05019073 1.02662538]Predicting the values
def predict(X):
global theta
F = f(X)
return dot(F,theta)
print("The error is :")
y_pred = predict(X_test)
print(mean((y_pred-y_test)**2))The error is :
0.09683797274423349A 3D plot showing the full picture
%matplotlib
fig = figure()
ax = fig.add_subplot(projection='3d')
X1 = tile(array([linspace(10,12,100)]),(100,1))
X2 = tile(array([linspace(1,4,100)]),(100,1)).T
Y = array([[predict(array([[X1[i,j],X2[i,j]]]))[0] for j in range(100)] for i in range(100)])
ax.plot_surface(X1,X2,Y,alpha=1)
ax.scatter3D(X_test[:,0],X_test[:,1],y_test,c='red')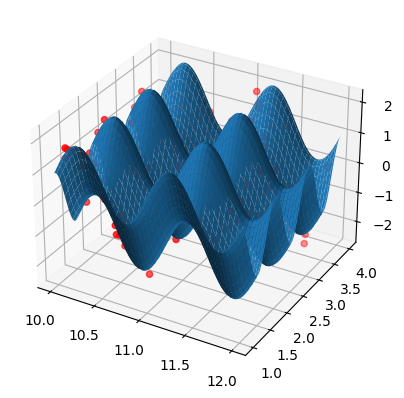
Example 2
Generating Data
x = (2*random.random(100) - 1)*pi
x = x[:,newaxis]
X = ones((100,1))
for n in range(1,4):
X = concatenate((X,x**n),axis=1)
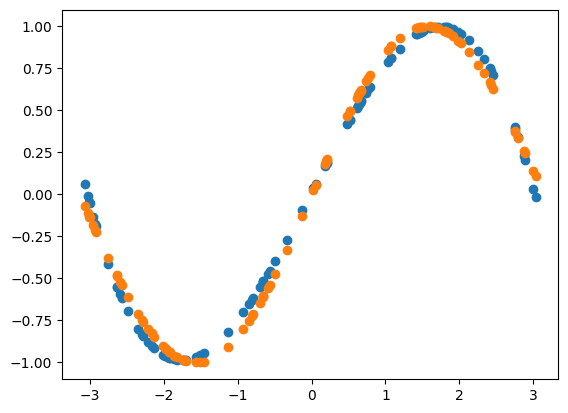
y = sin(x)We’ll consider the values of to be the features (conditions of measurement) and to be observations.
theta = dot(linalg.inv(X.T @ X) @ X.T ,y)[:,0]
print(theta)
y_pred = [dot(theta,X[i]) for i in range(shape(X)[0])]
plot(x[:,0],y_pred,'o')
plot(x[:,0],y[:,0],'o')[ 0.01508739 0.85071025 -0.00283029 -0.09259996]