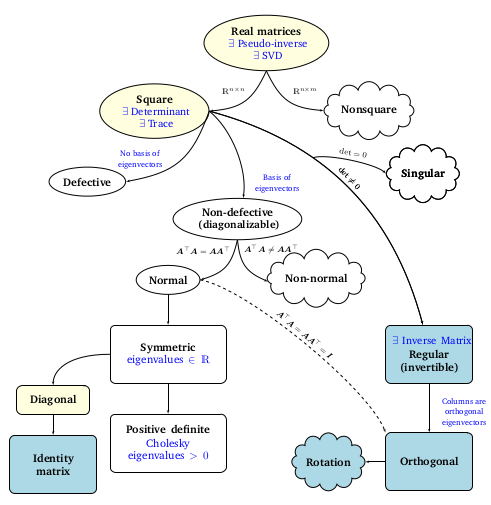
Matrix Decompositions
Trace of a matrix
It’s the sum of diagonal elements of a matrix and is the only function satisfying these 4 properties :
-
-
-
-
Using the last property, we can get , which means that similar matrices have the same trace, and thus for any linear map , no matter in what bases it’s expressed, as long as it has same bases on either side, (before the map and after the map), we get the same trace for the matrix representing the map.
Eigenspace and geometric multiplicity of eigenvalues
For a matrix , the Eigenspace of the eigenvalue , denoted by is the null space of .
The geometric multiplicity is the dimension of this null space and the algebraic multiplicity is the number of times this eigenvalue repeats in the roots of characteristic polynomial.
Eigenvalue properties
- A matrix and its transpose have the same eigenvalues (not the same eighenvectors) .
- Any linear map always has the same eigevalues, no matter how it is expressed , because the diagonal matrix in the decomposition stays the same (upto rearrangement)
- The sum of eigenvalues is just the trace and the product is the determinant (due to the characteristic polynomial) .
- Eigenvectors with different eigenvalues are linearly independent. Proof by induction : Suppose that this statement is true for eigenvectors, then consider any eigenvectors with distinct eigenvalues. Assume they are linearly independent, then we can write where at least 2 of the coefficients must be non zero. Applying the matrix on both sides, we get . Now subtracting times the first equation from this, we get : , which is basically screaming that eigenvectors are linearly dependent since not all of the coefficients are , which is a contradiction. And thus, we have extended the hypothesis to eigenvectors. The base case is for 2 eigenvectors and is trivially true.
Positive definite matrices
Any matrix such that where is a vector space is positive definite.
Positive definite matrices always have positive eigenvalues if they are real, since for any such matrix with any eigenvector with eigenvalue , we have .
Also, by putting the basis vectors instead of , we get that the diagonal entries must also be positive.
Although positive definite matrices don’t have to be symmetric, a lot of texts put the restriction in the definition itself. And I’m going to do the same. So when I say “positive definite”, I actually mean “symmetric positive definite”. Am I being a little bitch here ? Absolutely ! But you’ll just have to deal with it :)
Symmetric matrices
Any matrix which is equal to its transpose is symmetric.
Spectral theorem : if is a symmetric matrix, then the eigenvectors can be orthonormal and span the whole column space of .
Proof of orthogonality : Suppose are eigenvectotrs with unequal eigenvalues , then . But . Thus, . But since , so we have and thus are perpendicular if they have unequal eigenvalues. In other words, any two eigenvectors from eigenspaces of different eigenvalues are orthogonal. And we already know, that the eigenvectors in the same eigenspace can be chosen such that they are orthogonal. Thus we can create an orthonormal basis using all the eigenvectors.
The other fact that these eigenvectors span the column space is hard to prove. This fact allows us to write where are a diagonal matrix and an orthogonal matrix (rectangular or not), and are the eigenvectors and corresponding eigenvalues for any symmetric matrix . If is not symmetric , then is not an orthogonal matrix, but still has the linearly independent eigenvectors of as its column vectors, and the equation is still correct. This is called eigenvalue decomposition.
Producing symmetric positive semidefinite matrices
For any matrix (rectangular, singular, anything..), the matrix is symmetric positive semi-definite because 1) .. and 2) …. . If the matrix is also non-singular, then the last inequality becomes strict and our composed matrix becomes symmetric definite.
Now you might wonder if the reverse can also be done ? That is, get a matrix , given the matrix . It is certainly possible and can be done by the Cholesky Factorization
Cholesky Factorization
Given a symmetric matrix with rank , we can write where is an upper triangular matrix with rows and positive diagonal entries. On paper, this would look like this :
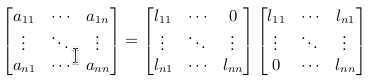
The first column vector on the RHS has the elements and thus first gives the value of and then all of . Now that you know the first column, you can easily form the equations for . Again, get first and then get all the other values. Keep repeating this procedure and you’ll end up knowing all columns of .
Singular Value decomposition
For any matrix , we can write where are orthogonal square (rotation) matrices with unit column vectors and is a diagonal matrix (with 0 padding where necessary) with entries . On paper it looks like this :
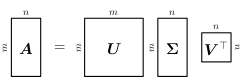
We can get by eliminating the other matrix like this :
and then performing eigenvalue decomposition of the matrices on LHS and assigning values to matrices. Note that the shape of is possibly different in both equations. this is accounted for by some entries in the bigger version being 0.
Notice that although it looks like it, is not the diagonal matrix obtained on eigenvalue decomposition of . But it can be if , since then the equation on the top is basicaly the eigenvalue decomposition. In that case, we have . This is a neccesary and sufficient condition for to be diagonalisable, or “normal” . In the other case, we say that is “deficient”.
The summation form in the topmost equation can be used to approximate the matrix as a sum of lower rank matrices. this is used in image compression. It’s also the value of the spectral norm of the matrix, which is the maximum scaling a vector receives when passed through the matrix. Basically, the spectral norm is :
The last equality is can be proved like this : The last equality is because is orthogonal
Eckart-Young theorem
Consider a rank- matrix with the singular value decomposition and the rank- approximation . For any rank- matrix with , we have , where equality happens when .
Proof : Since has rank , we can construct a vector that lives in the null space of using the first columns of . Suppose where is the matrix with as column vectors and is the column vector with entries . Also, suppose that the linearly independent column vectors as stacked up as row vectors to form , then the matrix has shape and thus the equation is solvable (because you can just do Gaussian elimination with some columns not being 0. Then find the specific solution by setting the coordinates in to 0 for such columns). Thus there is a vector that is orthogonal to all the linearly independent vectors in and is thus in the null space of .
The first inequality is due to the definition of spectral.
Mind Map
Yes, yes.. this isn’t my style, and neither is it yours, but since it’s given to us just like that, we might as well ..