The usual way you would recieve data is a matrix with rows being observations and columns being features. Every observation can be thought of as a vector, and these vectors are the empirical values for the “random variable” that is a general vector which is a list of such features. For example, for this matrix X :
⁍
The random variable x∈R2 , which is a list of features (scalar random variables), and has the observed values of [12]T,[34]T,[45]T and [56]T .
Note : Any random vector x is a column vector, unless stated otherwise.
The probability of of x taking a certain value x1 (in its full domain, not only in the observed values) is denoted as px(x1) , or for our convenience, simply as p(x) .
If the case that the domain of x contains infinite elements and the probability for one value is infinitesimal, p(x) refers to the probability distribution function, but I’ll still refer to it as the “probability” as if we are always taking about a discrete dirtribution.
For an event described by multiple random variables, the probability is written as p(x,y,z,…) . In such a setting, if there are less random variables inside the bracket than required to describe the event, then we are talking about the probability of any of the events with the specified random variable taking the values in the brackets, regardless of what values the other random variable take. For example, if an event is described by three random variables x,y,z , then p(x,y)=∑zp(x,y,z) .
Since we can always concatenate multiple random variables describing an event in a single big vector, so we only need to talk about 2 random variables at max.
We use ‘ ∣ ‘ to mean “given” it is used to denote conditional probability, defined (yes, I’m using this equation to define the probability, rather than the usual set theory based definition) as
p(x∣y)=p(x)p(x,y)
This is the probability of and event having a certain x , given that it has y as specified.
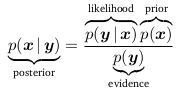
From here it’s easy to derive Baye’s rule.
Bayes’ rule
One good example where it’s used is the Gaussian Naive Bayes’ Classifier.
A simpler example would be the β-distribution, which is probability distribution of the probability θ of a person winning a match, if we know that he has won α matches and lost β assuming that this probability of winning stays the same in every match. Here we are trying to find p(θ∣α,β) . we already know that p(α,β∣θ)=α+βCαθα(1−θ)β and we can find p(α,β) by integrating p(α,β∣θ) over θ , which gives us α+βCα(α+βCβ(α+β+1))−1=(α+β−1)−1 and we assume that p(θ)=1∀0≤θ≤1 and 0 otherwise. This gives us that :
Using Bayes’ rule if you have some prior pdf for x , given more data in the form of vectors yi used as row vectors in the matrix Y , you can update x . We want to find the posterior pdf for x , that is p(x∣Y) . This is calculated as p(Y)p(Y∣x)p(x) . Since the observations are all independent to each other, thus we can break this as ∏ip(yi)p(yi∣x)p(x) . This means we need to know p(x∣y)=p(y)p(y∣x)p(x) first. If y was in the same domain as x , then we could just calculate p(y∣x) to be the delta function in x centred around y , and then we would get the same for p(x∣y) . So it makes no sense to take them to be in the same set of features. Although, we can certainly take them to be in a set of dependent features.
Statistically Independent variables :
Two random variables x,y are statistically independent iff p(x,y)=p(x)p(y) .
Expected values
For a function f(x) of the random variable x , the expected value is given by :
E[f(x)]=x∑f(x)p(x)
It’s easy to see that E(x) is the mean of x .
Note : The definition is only valid for discrete distributions
Covariance and variance
Suppose you you want to know how much are 2 feature x,y similar (linearly dependent), given some data in the form of a matrix X with these two features present in the observations, then you can just take the dot product of the column vectors of these two features after subtracting the mean from each entry (This is important to do as if these quantities don’t vary a lot but have high values all the time, then the covariance of such quantities must intuitively be small). Then, divide by the length of the column vectors since you don’t want this value to depend on the size of the data-set. This quantity is called the covariance. Basically,
The last equality is obtained by expanding the square inside the summation and using the fact that E(x) is a constant.
The covariance can be used as a definition of an inner product between two random variables. Then the induced norm would be the square root of the variance. And the angle θ between two random variables x,y would be given by :
cos(θ)=Var(x)Var(y)Cov(x,y)=corr(x,y)
This value is called the “Correlation” .
When the random variable x is a vector, we can express the covariances of all pairs of features xi,xj in a covariance matrix, which is basically the “Variance” of x .
Random variables x1,x2,x2,…,xn are independent and identically distributed if :
They are statistically independent , i.e. p(x1,x2,…,xk)=p(x1)p(x2)…p(xk)∀k≤n
All of their distributions are the same function. This can be summarised as : xi=xj⟹p(xi)=p(xj) .
It’s easy to see that in a case like this, the variables are also linearly independent .
This is useful when you want you take n observations with each observation coming from the same distribution and predict beforehand the properties of these observations. For example, the expected value of the computed mean of observations xi is the same as the expected value for a single observation, say μ, and the variance is thus E((n1∑ixi−μ)(n1∑ixi−μ)T)=n21E((∑i(xi−μi))(∑i(xi−μi))T)=n21∑i∑jE((xi−μi)(xj−μj)T)=n21∑i,jCov(xi,xj)=n21∑iCov(xi,xi)=n21∑iVar(xi)=n21(nΣ)=n1Σ
The 4th equality is because of the linear independence of the variables.
Gaussian distribution
This distribution is important to the next theorem. Although it lacks physical meaning, it has immense mathematical meaning.
For a random variable x∈R , if it follows the Gaussian distribution
p(x)=2πσ21exp(−2σ2(x−μ)2)
then it has mean μ and variance σ2 , where σ=Var(x) is the standard deviation .
To make life simpler, every time we want to say that a variable x follows a Gaussian distribution with mean and variance μ,σ2, instead of saying it in words, we write x∽N(μ,σ2).
For a vector valued random variable x∈Rn , made of statistically independent scalar Gaussian random variables x1,x2,…,xn with xi∽N(μi,σi2) , we have :
then if E(x)=μ and Var(x)=Σ , we have ∏iσi2=∣Σ∣ and ∑iσi2(xi−μi)2=(x−μ)TΣ−1(x−μ) , giving us :
p(x)=(2π)n∣Σ∣1exp(−21(x−μ)TΣ−1(x−μ))
It turns out that this equation is valid even when xi,xj are NOT { independent OR Gaussian } , but x overall is Gaussian .
Marginals and conditionals of Gaussians
Suppose x,y are two random variables, which together (concatenated) form a random variable z=[xTyT]T which we know to be Gaussian, and suppose we want to find out the distribution of x given the value of y (Perhaps you want to predict something about a point with a specific y ). We do that by taking the conditional distribution p(x∣y) . This method isn’t specific to Gaussian distributions, but here we are interested in the result obtained when we consider Gaussian distribution specifically. Basically, to find p(x∣y), you need to find p(x) , which we’ll prove to be a Gaussian distribution N(μx,Σx,x) .
(Say that Σa,b=Cov(a,b) and μa=E(a) for any two random variables a,b .)
Rather than brute forcing our way through complex linear algebra, we’ll prove this inductively, by proving this for a scalar valued y, say the last coordinate of z to get a reduced set of coordinates being in a guassian distribution, and then using the fact that we can do this over an over and over untill we eventually delete an arbitary number of arbitary coordinates, making this true for any general x,y .
First let’s write the covariance and mean of z in terms of x and y
Σz,z=[Σx,xΣy,xΣx,yσy2] and μz=[μxμy]
You are free to verify that the inverse of any positive definite symmetric matrix S=[ABTBD] where A,B,D are sub-matrices is also positive definite symmetric, say [A′B′TB′D′] .
In our case A=Σx,x,B=Σx,y,BT=Σy,x,D=σy2. In favour of my sanity, I’ll use A,B,D for the linear algebra rather than bold greek symbols with subscripts all the time. Also, let’s call p=x−μx and q=y−μy .
Now since ∫−∞∞exp(−21(q+D′pTB′)2)dq=2π and other stuff is constant wrt q, thus we only have to worry about pT(A′−D′B′TB′)p inside the exp function (except the -1/2) after the integration is done. Namely, p(x)αexp(−21(x−μx)TM(x−μx)) where M=A′−D′B′TB′ is some constant square matrix. Now after normalising the expression to get a pdf, we’ll just end up getting a normal distribution x∽N(μx,M) . What this means is that M=Σx,x−1 , which isn’t surprising because the way it was defined, it’s basically A−1 . And thus, using the inductive method I proposed, we can say that for any random variable formed by deleting some coordinates (more than one) of z , say x , has a normal distribution .
it’s easy to see that the thing inside the exp function (except the -1/2) is a symmetric quadratic form in x, and can thus be expressed as (x−a)TM(x−a) for some symmetric matrix M . Thus p(x∣y) is also a normal distribution. To find the parameters of this distribution, you have to get your hands dirty and do a lot of linear algebra involving block matrices. I am going to skip all of that and just give the results to you :
For probability density functions py(y) and px(x) for variables x,y related as y=f(x) , we have py(y)dy1dy2…dyn=px(x)dx1dx2dx3…dxn
We know that the determinant of the Jacobian of y wrt x gives us the factor by which the volume dx1dx2dx3…dxn scales to become the volume dy1dy2…dyn ..Thus, we can write py(y)∣Jf(x)∣=px(x) .
Affine Transform of a Gaussian variable
Consider x∽N(μx,Σx) . Then, for a variable y=Ax+b , we have
Consider y∽N(μ,Σ) . This is the result of an affine transformation on x∽N(0,I) given by y=Ax+μ for some A such that AAT=Σ . We know how to find a possible A using the Cholesky Decomposition .
Thus all Gaussian variables are just Affine Transformations of the Standard Gaussian x∽N(0,I) .