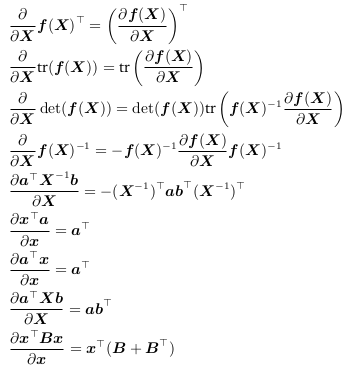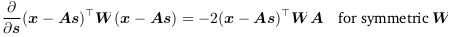For a scalar valued function f with vector valued input x∈Rn , the derivative is this row vector of shape 1×n .
dxdf=∇xf=[∂x1∂f∂x2∂f…∂xn∂f]
This is the vector along with rate of increase of f (wrt norm of displacement) is highest.
Jacobian for vectors
For a vector valued function f(x)∈Rm with vector valued input x∈Rn , the derivative is this matrix of shape m×n called the Jacobian matrix, or simply the Jacobian :
dxdf=∇xf=J where Jij=∂xj∂fi
Jacobian for Matrices
For a matrix valued function f(x)∈Rp×q with matrix valued x∈Rm×n , the derivative is again the Jacobian J which is now a tensor of shape p×q×m×n , which can’t be written on paper. J is given by its elements instead as :
Jijkl=∂xkl∂fij
But this approach is impractical and what is usually done is that the matrices f,x are flattened out into vectors of size pq and mn , and then the Jacobian matrix with respect to these vectors is calculated.
Useful identities for calculating Jacobians
Automatic differentiation
Sometimes the derivative of a complex function (a function composed of many small functions) is even more complex than the function itself. Suppose f is such a function composed of n simple functions, as f=fn∘fn−1…f2∘f1 and f′ is composed of m>n simple functions. Then instead of computing the derivative directly, we can keep track of the values of k succesive functions applied on the current input as xk=fk∘fk−1∘fk−2…f2∘f1(x) . Then using dxdxk=fk′(xk−1)dxdxk−1 , we calculate the derivatives of all xk and update them by adding the derivative times the step. Thus, in the last iteration of every (full) update, we arrive at f′(x)=dxdxn . Here, we’ve done only n simple computations rather than m computations done when using the explicit form of f′ . Note that it’s important that you update every xi only after you have used it to calculate f′(xk−1) . Also in practice, the equation you would use is not dxdxk=fk′(xk−1)dxdxk−1 , but just Δxk=f′(xk−1)Δxk−1 .
This can also be generalised to functions composed of vector valued simple functions with vector valued inputs.
Second order derivative wrt a vector
For a scalar valued function f(x) with inputs x∈Rn , the first order derivative is dxdf=[∂xi∂f]iT where the square bracket means “stack one below other for different i” , i.e. create a column vector with such and such entries. Notice that the structure in which the vectors are represented doesn’t matter all that much, the containment does. (if you have ever used the numpy library in python, you know what I’m talking about) So now, the 2nd derivative is dxd([∂xi∂f]i)=[∂xi∂xj∂2f]ij=H , also known as the Hessian.
You can also think of this as ∇T∇f where ∇=[∂x1∂∂x2∂…∂xn∂] .
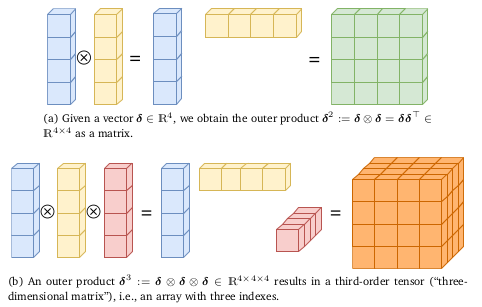
To go to the third derivative, we need a generalised notion of matrices that doesn’t depend on the orientation and other trivialities. thus we use tensors and the outer product, which behaves like matrix multiplication :
Now, we define ∇xk to be the k-th total derivative wrt x , which is given by taking k outer products of the nabla operator. Basically, ∇xk=∇⊗∇⊗∇⊗…∇ (k times).
Multivariate Taylor series
For an analytical function f(x) , if x=x0+δ , then we have the taylor series :
f(x)=k=0∑∞k!∇kf(x0)⋅δk
Here δk=δ⊗δ⊗δ⊗…δ is the outer product of δ taken k times. we are taking the inner product of ∇kf(x0) and δk as